
Tackling Compounding Errors in AI Agents
AI Agents have the potential to change business, but the risk of compounding errors requires caution and mitigation.

Everywhere you look people are saying AI Agents are the future. While the definition of what an Agent is depends on who you ask, in my book it’s a programmatic solution that leverages LLMs to make decisions and perform or guide actions without human intervention. At the beginning of the AI hype cycle as a consultant in the space we always said that there would be a human in the loop. The narrative seems to be shifting where the human element is removed or minimized to the fullest extent. So if you believe the shifting narrative and you want to start seeing what it can do what risks do you need to be worried about? Today I’m focusing on compounding errors.
Compounding Errors in Agents
Statistics are not innate to humans. Studies have consistently shown as a species we are not good at understanding risk. So a quick intro stats refresher. Colloquially you probably have heard about the effects of compounding in relation to retirement savings. Start saving for retirement now, because the returns compound on themselves. If you put in $100, it goes up by 10% in year 1, then starting year 2 you have $110 when it goes up 10% again now you have $121. You earned $1 on the $10 you made in year 1.
So what does this have to do with AI agents? I’m going to extremely simplify how agents work. Agents perform a series of actions using LLMs to guide or perform tasks. Even with all the improvements in generations of LLMs there is still the risk of hallucinations and or a misunderstanding from a prompt. Each time an LLM produces an answer there’s a chance it fails. Agents will make lots of steps to get complete a single request. If we look at it graphically, the more steps an agent takes the likelihood of a failure increases. Modeled below is 5 success rates from 2-20 steps.
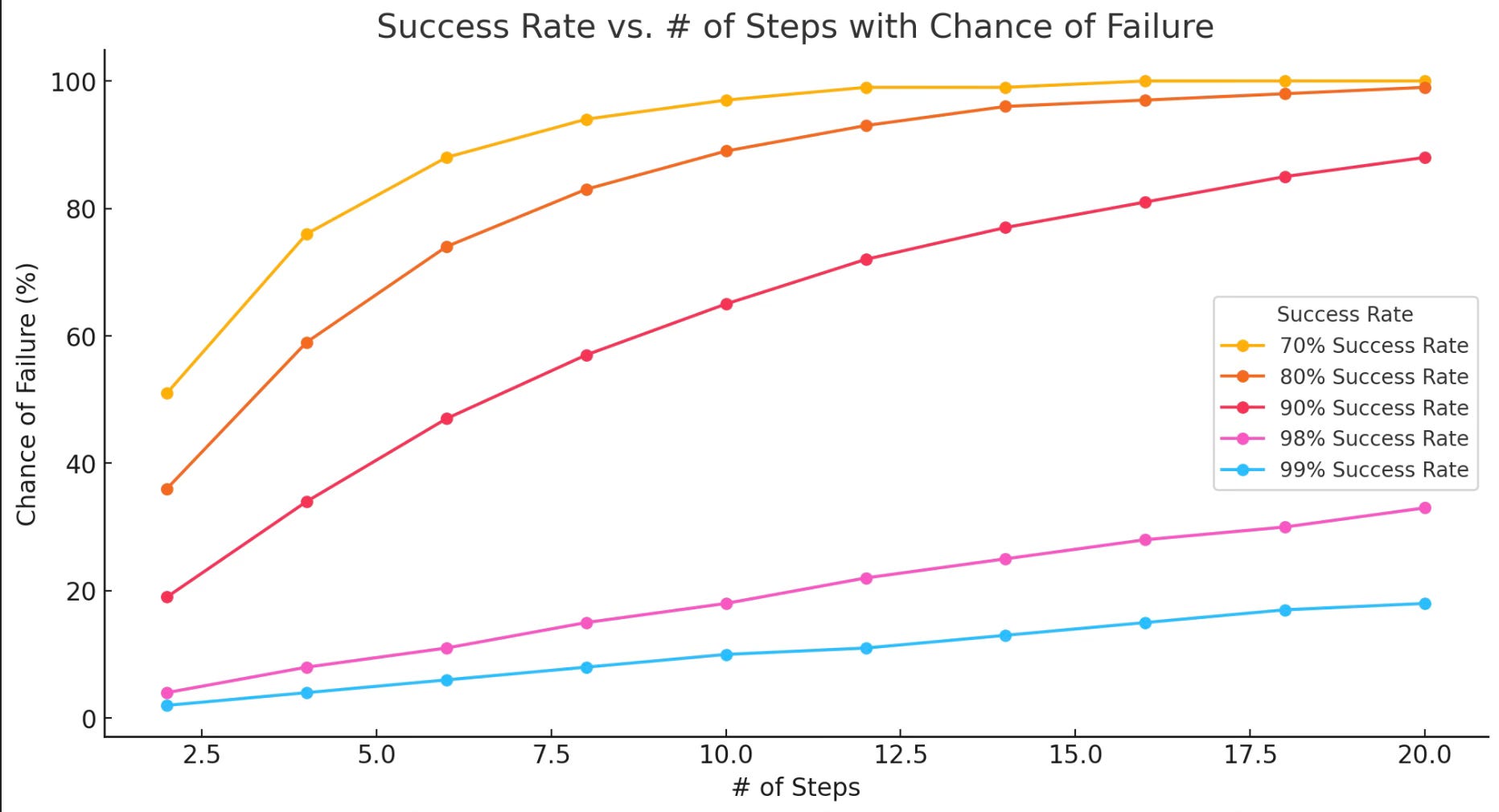
As you can see, the more steps an agent takes without human intervention the risk of failure creeps up quickly. Even if you think you have you agent dialed in an average 99% success rate, at 20 steps 1 in 5 times it will have made at least 1 mistake.
In the Real World
Last night I was using Gemini’s Deep Research tool1 and I encountered an issue where it was making an incorrect choice during its process and it returned an answer completely different than what I was looking for. Here is my initial prompt (I sensitized a little):
If I am work at a [company type] that specializes in [Activities], what are some of the [sales opportunities] I would want to check for a perspective client using their website and financials?
What I was hoping to get back was a list of metrics and factors I could use to build out sales channels, but instead I got back a detailed report on Coca-Cola. I’m not sure where it went wrong, but somewhere in the 70+ websites it found and the steps it ran over 15 minutes it got stuck that it was writing a report on Coca-Cola’s performance. I’ve continued to use Deep Research and I haven’t had as egregious of an error again, but it does sometimes seem to fixate on pieces of information that I wouldn’t have thought are relevant or noteworthy.
So if you wanted to build out an agent what can you do to mitigate your risk of failure?
Questions You Should Ask and Steps You Should Consider
I highly recommend you start small. One thing that likely makes an agent like Deep Research difficult is they are trying to have a universal research agent. If you start small with an agent that just does one task it’ll be infinitely easier to answer the following questions:
What is my risk appetite? How many steps are you comfortable with an agent performing before someone checks in?
I still think of AI as a first year analyst. How long would you give an analyst before you wanted a check in? As you’re building it out and testing it add stop points where you can insert feedback throughout the process
Pick something low risk to start and build complexity later.
What checks can I add along the way?
Are there clear rules you can add in? Maybe there are critical milestones or actions where you need to add a stop or check condition.
An adversarial AI can be used as a judge throughout the process. Checking after each step with the express purpose of finding something wrong and providing feedback (Whether it’s stop or try that step again with this in mind)
Define your scope for this POC and watch scope creep. It’s easy to get excited and try to solve everything. Keep it simple the first time.
What can go wrong?
When you’re automating something you can’t just think about what happened this time or last time. You need to think of all of the possibilities and make a plan for them.
I like to bucket them based on the scope of my project. Any automation should be able to handle anything that is “normal” and at least a handful of common exceptions. That also means you should have flags to highlight if things have really gone off the rails. Always think completeness and accuracy.
AI works best in concert with other tools and with people. When you’re thinking of building out agents think about where and when people should be involved and how other technologies can provide checks throughout the system to reduce the chance of errors.
Super cool btw. Check it out if you haven’t it takes a single prompt and goes out finds sources (I’ve seen up to 160 websites) and writes a compelling research report.